

Common CI Pipeline Considerations: Ordering and Caching
How using a table during the planning step could have saved a lot of headache.

I'm a developer from Vancouver, BC who's had an interesting journey in tech starting from support, through cloud infrastructure and project management. Currently I work as an SRE at lightstep helping build and "operationalize" things that helps to guide others towards better o11y :)
At work last week, I found myself getting burned by ordering and "file doesn't exist" errors. Ultimately - the thing that (would have) helped me get past most of these issues is something that I can't believe I forgot: a table.
If you've been following along with my last two blog posts, I've been tasked with implementing a check on PR to validate dynamically generated configuration files for a service running Open Telemetry Collectors.
To do this we had to:
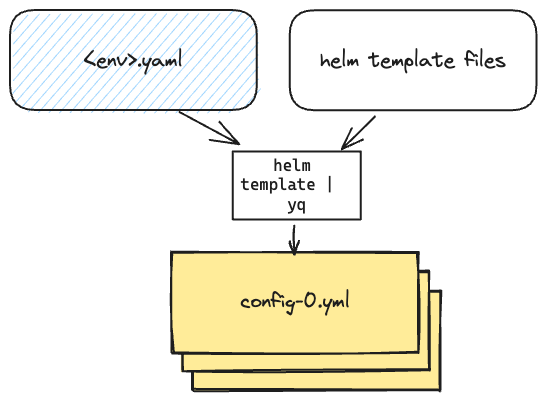
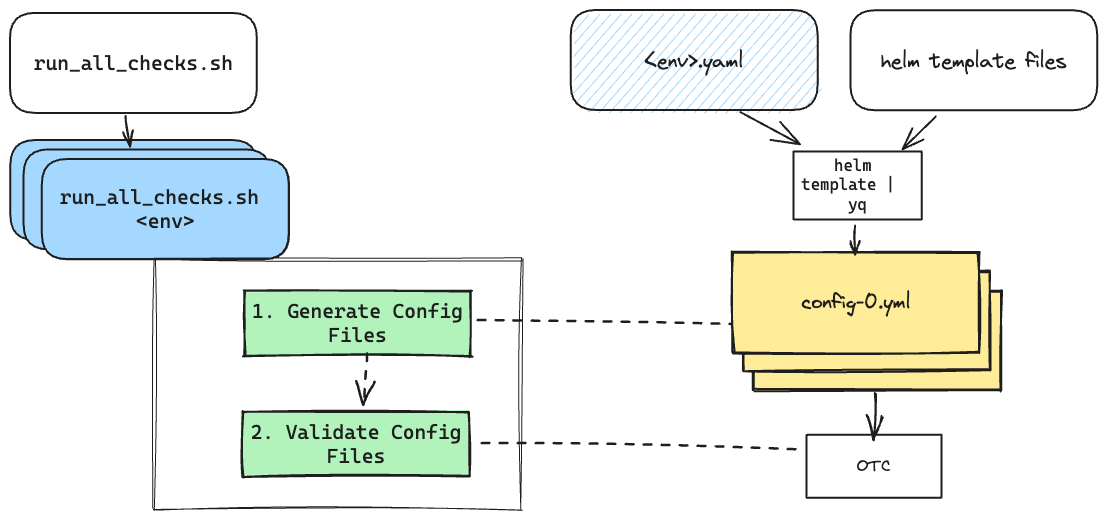
You'll recall that the goal from Step 2 was to get this running successfully on my laptop so we could then set it up to run on CI.
Which brings us to today.
Setting this up in CI
At this point, I had a working script that I simply had to run on my Continuous Integration (CI) pipeline on each PR. We currently use CircleCI so that meant updating our /.circleci/config.yml file which looks something like this:
workflows:
version: 2
build_and_test:
jobs:
[...]
- test-my-service-build
So I figured, maybe I'd just add a new job called validate-my-service-config which would checkout the repo and run anytime any code changed in our Helm chart (where the config files were defined).
Perhaps something like this:
workflows:
version: 2
build_and_test:
jobs:
[...]
- test-my-service-build
- validate-my-service-config
###
validate-my-service-config:
working_directory: /home/circleci/workspace/myrepo
# Run this step in a Docker container using the docker image we've
# sepc'd in pipeline params.
docker:
- image: cimg/go:<< pipeline.parameters.golang-image-version >>
steps:
# Git checkout the repo
- shallow-checkout
# Check if the charts dir has changed which contains the config
- check-if-code-changed:
path: kubernetes/charts/my-service
- run:
name: "validate-my-service-config"
command: |
export MYREPO_REPO_ROOT=/home/circleci/workspace/MYREPO
export PATH=$MYREPO_REPO_ROOT/bin:$PATH
# make validate-all-configs runs run_all_checks.sh
make -C kubernetes/charts/my-service validate-all-configs
But there arose two new problems:
This step runs in a Go Docker image, it doesn't have
Helmonboard; andThis step runs the
make validate-all-configstarget which runsrun_all_checks.shscript which expects themy-servicebinary to be present in a specific file location, but what if the binary doesn't exist in the expected location at the time of running?
Dependency: Install Helm
Installing Helm was easy thanks to a make target that was created by SREs before me, called make install-helm (it would fetch the script from get.helm.sh, uncommpress it, and install from source)
Dependency: Ensure that the
my-servicebinary is available before the script runs.
This is where ordering became important. You will recall from further up that our CircleCI workflow had a job called test-my-service-build which was used to test and confirm that the binary would, in fact, build.
test-my-service-build:
working_directory: /home/circleci/workspace/myrepo
docker:
- image: cimg/go:<< pipeline.parameters.golang-image-version >>
steps:
- shallow-checkout
- check-if-code-changed:
path: go/src/github.com/myrepo/my-service
- run:
name: "build"
command: |
export MYREPO_REPO_ROOT=/home/circleci/workspace/myrepo
export PATH=$MYREPO_REPO_ROOT/bin:$PATH
make -C go/src/github.com/myrepo/my-service build
I initially thought:
Sweet! Maybe I'll just run the validation steps inside of testing the image, because that way the binary will be available AND it kills two birds with one stone.
(Also, on a completely random tangent, that Idiom always reminds me of this comic by Nathan W. Pyle)

Anyways, it would look like this:
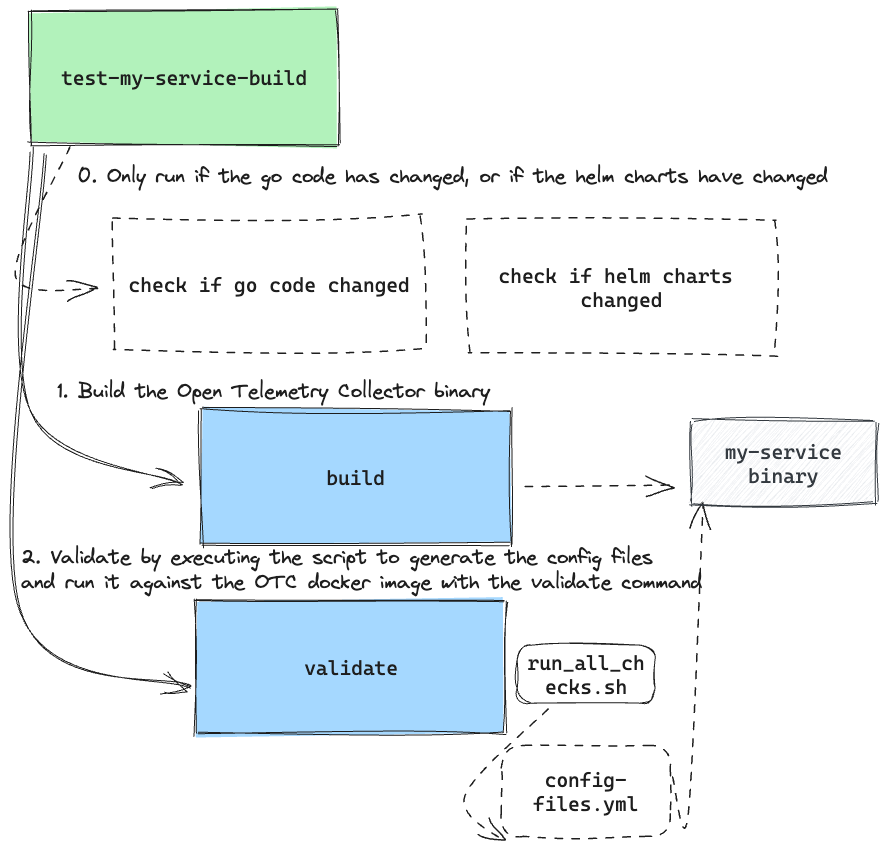
test-my-service-build:
[...]
# Check build AND config paths for changes
- check-if-code-changed:
path: go/src/github.com/myrepo/my-service kubernetes/charts/my-service
- run:
name: "build"
command: |
[...]
make -C go/src/github.com/myrepo/my-service build
- run:
name: "validate"
command: |
[...]
make -C kubernetes/charts/my-service validate-all-configs
But I had to quickly disqualify that idea. Mainly because test-my-service-build was (1) specifically "targeted" to run on file changes to the go source and (2) only check the build. Doing config validation in this step felt like inappropriate overloading;
What would happen if we only needed to check config, or only check build? Is it appropriate that we have to do the other step as well?
More specifically, this is inappropriate because it could lead to situations where we are unable to make a build related change because config is bad, and vice versa. This creates unnecessary coupling between the two.
| Go Code Changes | Helm Config Changes | Result |
| ✍🏾 | None or ❌ | A PR dealing with Go Code would be blocked due to a Config issue |
| None or ❌ | ✍🏾 | A PR dealing with Helm congig changes would be blocked due to a Go Code issue. |
Okay what if we made
test-my-service-builda pre-requisite forvalidate-my-service-config?
Something like:
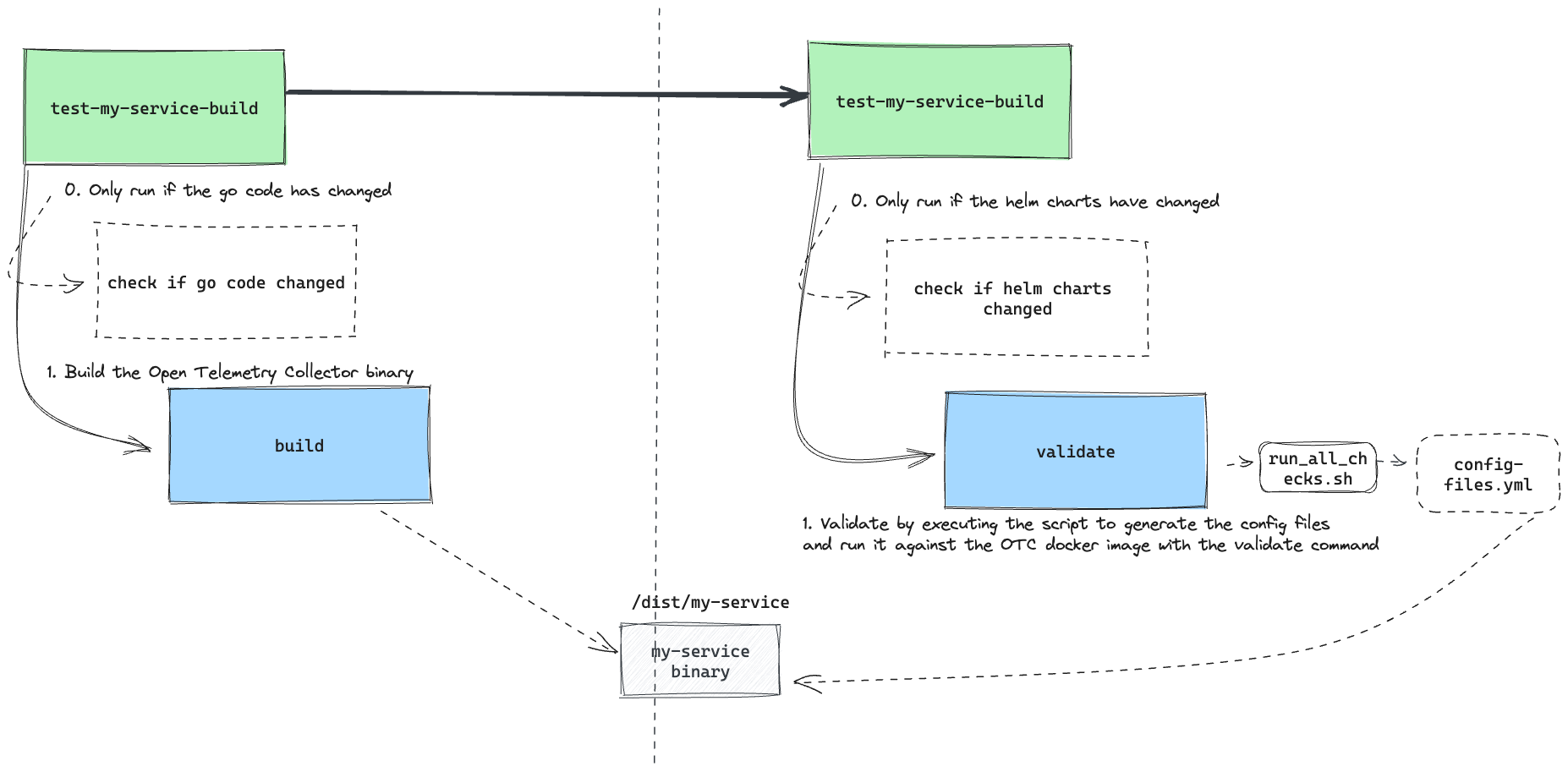
workflows:
version: 2
build_and_test:
jobs:
[...]
- test-my-service-build
- validate-my-service-config
requires:
- test-my-service-build
Since the binary is built in test-myservice-build, it would ensure that the binary is available on the file system for validate-my-service-config
But there was a problem with this approach:
Incorrect Targeting
Since test-my-service-build was targeted as follows:
test-my-service-build:
[...]
# Check build AND config paths for changes
- check-if-code-changed:
path: go/src/github.com/myrepo/my-service
It would never actually build if there was a change to config, meaning that the binary would never be built and thus be available for the validate-my-service-config job, which is getting back to Square 0.
| Go Code Change | Helm Config Change | Result |
| ✍🏾 | CI would work as intended ✅ | |
| ✍🏾 | This would fail because changes were not made in the directory that's targeted by test-my-service-build and thus the required binary would not be available. |
Okay okay, what if we made
validate-my-service-configdo it's own build?
Something like this:
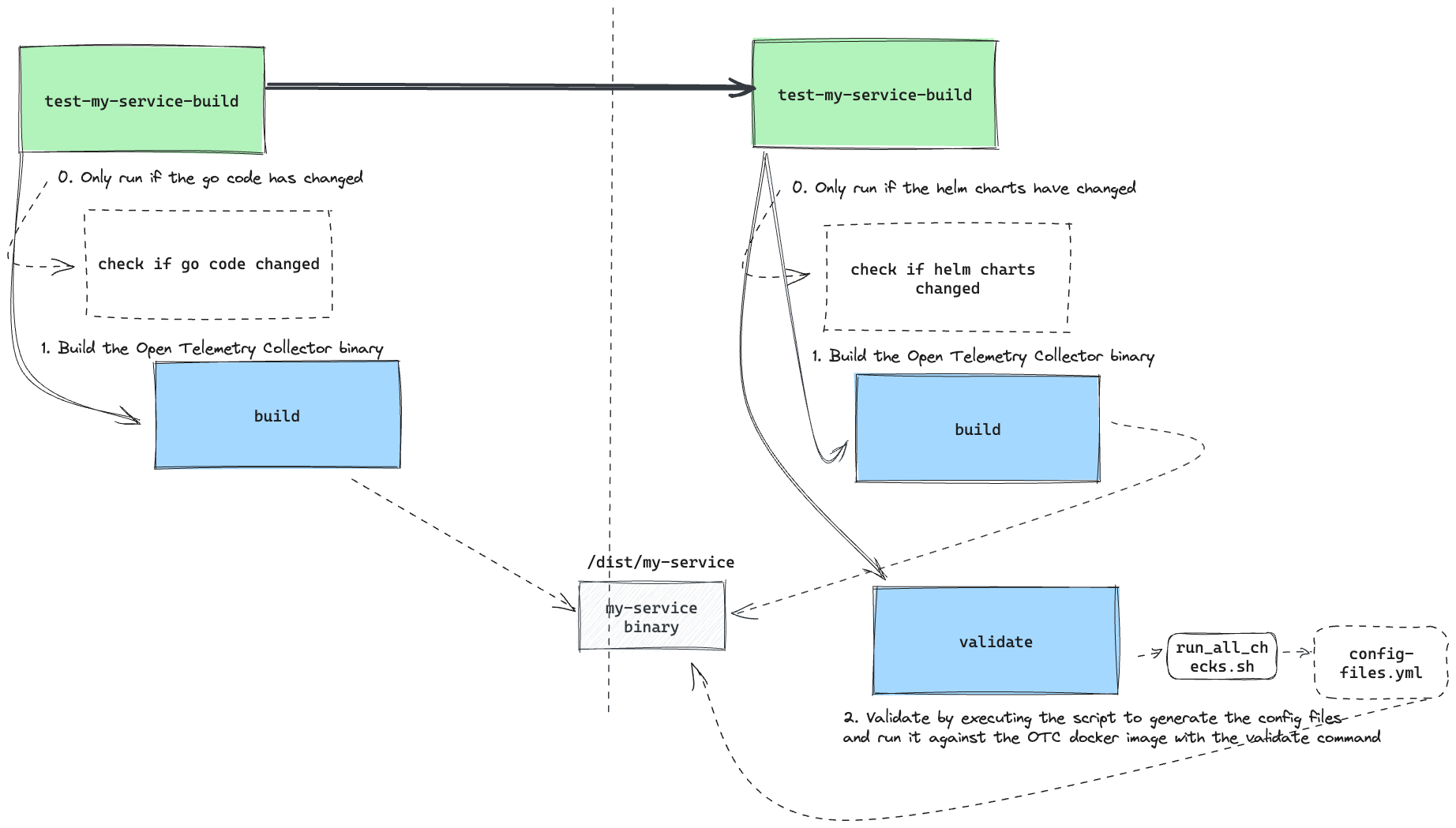
In Code:
validate-my-service-config:
[...]
# Check build AND config paths for changes
- check-if-code-changed:
path: kubernetes/charts/my-service
- run:
name: "build"
command: |
[...]
make -C go/src/github.com/myrepo/my-service build
- run:
name: "validate"
command: |
[...]
make -C kubernetes/charts/my-service validate-all-configs
Inefficient
This setup would mean that the my-service binary would need to get built twice if there was an incoming change that required changing Go code and Helm config.
| Go Code Changes | Helm Config Changes | Results |
| ✍🏾 | 1. Triggers test-my-service-build which builds the my-service binary | |
| ✍🏾 | 1. Triggers validate-my-service-config which (1) builds the my-service binary and (2) validates config | |
| ✍🏾 | ✍🏾 | 1. Builds the binary in test-my-service-build |
2. Builds the binary again in validate-my-service-config |
This was starting to feel like inappropriate overloading again.
Okay okay okay, what if - we made use of caching to cut down on the amount of image building we did?
Yes. This would work. CircleCI has a couple of strategies for persisting data between jobs and workflows and for our use case we picked caching.
Specifically:
test-my-service-build➡️ will always build the image, and then save to thecache.cache➡️validate-my-service-config➡️cache- where the cache is made available to the validate step.If the binary exists in cache, use that.
If it doesn't, create it!
If a binary is created, save it to cache!
This solves our problem as follows:
| Go Code Changes | Helm Config Changes | Result |
| ✍🏾 | Always builds the image, and saves to cache. | |
| ✍🏾 | Reads from cache to fetch a binary if it was recently built, and if not, creates the binary and saves to cache. | |
| ✍🏾 | ✍🏾 | Will build the image ONCE in either step (and then save to cache), and that same image will be used in the second step. (The image only gets built once) |
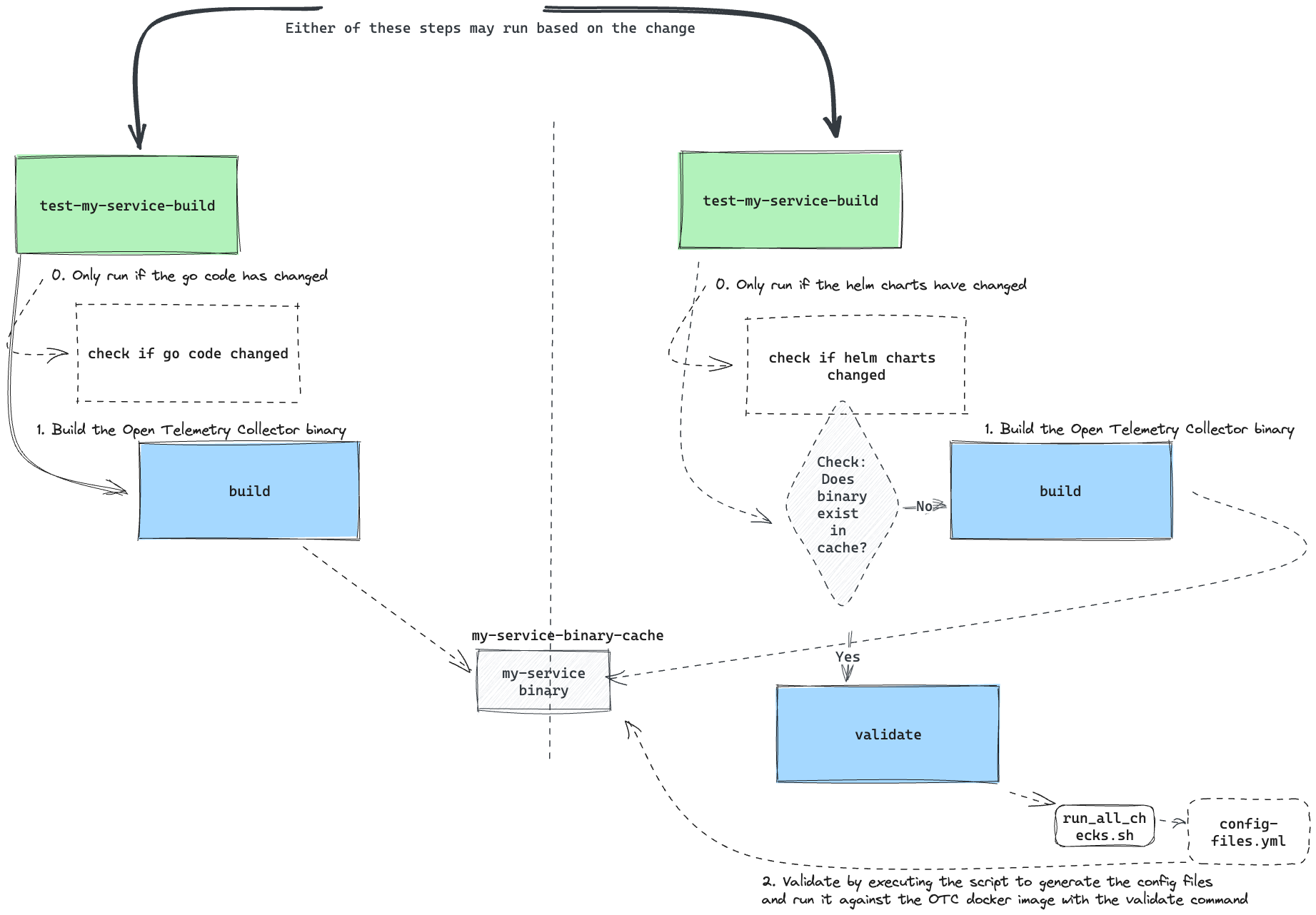
This is what that looks like in CircleCI config:
workflows:
version: 2
build_and_test:
jobs:
[...]
- test-my-service-build
- validate-my-service-config
###
test-my-service-build:
working_directory: /home/circleci/workspace/myrepo
docker:
- image: cimg/go:<< pipeline.parameters.golang-image-version >>
steps:
- shallow-checkout
- check-if-code-changed:
path: go/src/github.com/myrepo/my-service
- run:
name: "build"
command: |
export MYREPO_REPO_ROOT=/home/circleci/workspace/myrepo
export PATH=$MYREPO_REPO_ROOT/bin:$PATH
make -C go/src/github.com/myrepo/my-service build
- save_cache:
key: my-service-binary-cache
paths:
- go/src/github.com/myrepo/my-service/dist/my-service
###
validate-my-service-config:
working_directory: /home/circleci/workspace/myrepo
docker:
- image: cimg/go:<< pipeline.parameters.golang-image-version >>
steps:
- shallow-checkout
- check-if-code-changed:
path: kubernetes/charts/my-service
- restore_cache:
keys:
- my-service-binary-cache
- run:
name: "validate-my-service-config"
command: |
export MYREPO_REPO_ROOT=/home/circleci/workspace/MYREPO
export PATH=$MYREPO_REPO_ROOT/bin:$PATH
# Check if a binary exists in the cache
my-servicebin="go/src/github.com/myrepo/my-service/dist/my-service"
if [ ! -e "$my-servicebin" ]; then
echo "my-service binary does not exist."
make -C go/src/github.com/myrepo/my-service build
fi
make -C install-helm
# make validate-all-configs runs run_all_checks.sh
make -C kubernetes/charts/my-service validate-all-configs
- save_cache:
key: my-service-binary-cache
paths:
- go/src/github.com/myrepo/my-service/dist/my-service
Learnings
By understanding the ordering required by our CI steps and utilizing the use of Circle CI's cache, we are able to ensure that the dependencies for each step are met and that we're being efficient in doing only the steps required for each type of change.
As you saw from each of my iterations on changing the CI pipeline, I ended up having to build a table to test if that configuration would satisfy each use case (i.e.go change, helm change, go & helm change); If I were to do this again in the future, I think I would make that table, a part of my design and planning process.
For example:
| If there's a Go Change (Binary) | If there's a Helm change (Config) | What should we test in CI? |
| Yes | No | We only need to test that the binary is built successfully. |
| No | Yes | We only need to test that the config files can be validated against the binary. Prerequisite: |
| Yes | Yes | The binary must be built AND the config files must be validated. But we only need to build the binary once - good opportunity to use caching. |
| No | No | Nothing is required, kick back and relax. |
Considerations:
The binary must be built for every go change
The binary must be built prior to testing a helm change, but it may run after the go binary is built in
test-my-service-build- this might be a good opportunity to use caching.
Conclusion
In conclusion, understanding the ordering of CI steps and utilizing CircleCI's cache feature can help ensure that dependencies are met efficiently for each type of change. Creating a table during the planning process can help anticipate different scenarios and optimize the CI pipeline accordingly.



