

Lessons Learned - Sharpening my Bash Skills
A practical guide in using Bash to solve a real-world problem with examples.

I'm a developer from Vancouver, BC who's had an interesting journey in tech starting from support, through cloud infrastructure and project management. Currently I work as an SRE at lightstep helping build and "operationalize" things that helps to guide others towards better o11y :)
Bash scripting is one of those things that I always associate with a strong engineers and especially those in SRE. Conversely, it's not something I get to write a lot of and so - I'll take any opportunity to sharpen those skills.
This blog post explains how to set up a CI pipeline to validate config files for Open Telemetry Collectors (OTCs). It includes a bash script that checks a config file and deletes the directory if the config check passes, and also uses getopts to parse command line arguments and assign values to them. Additionally, I talk about the Shellcheck VS Code Extension which can be used to quickly fix linting errors.
Background
For the past 2 weeks, I've been continuing my task of setting up our CI pipeline to support config file validation for our Open Telemetry Collectors (OTCs). This is a continuation of the work I've been doing in my last blog post
On the surface - this task seems pretty easy:
You build an Open Telemetry Collector (OTC)
You grab a config file
You feed the config file into the OTC using the
validatecommand like so:opentelemetry validate --config <config_file.ymlwhich exits with0if valid; andYou do this in your CI (Continuous Integration) pipeline to ensure that the config files you're going to be deploying with, are valid
Easy peasy right?
Not quite.
Problems & Work to be Done
There were a couple of problems and todo items that arose:
What do you do when the config files are not statically laying around on disk, but are dynamically generated at deploy-time using Helm? ✅ Solved! You can read how we did this with a nifty
yqsnippet here: https://tratnayake.dev/understanding-helm-templates-and-utilizing-yq-for-yaml-parsing-mastery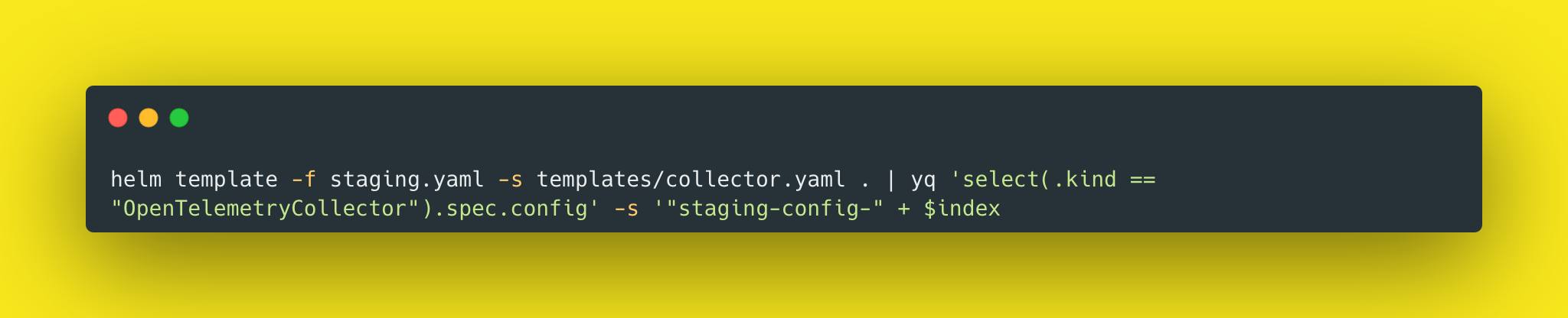
How do you get your CI system to ✨ do the things ✨ (build the OTC, template out the Helm files)?
As with most things, I figured the first step would be to try doing this on my laptop first:
💡 If I can get this working on my laptop via some scripts, I can then tweak those scripts to work on CI.
Enter, Bash.
Bash baby, Bash.
I decided to set this up through a system of scripts:
checks/run_all_checks.shwhich would enumerate the environments thatmy-servicewas running in, and then based on each environment would run:checks/run_checks.shwhich would:Create a
checks/test_generated_configs/<env>directoryRun the
helm templatecommand from above and render out all the config files into that directoryIterate through each of the config files and run them through the OTC binary (found at a specific file location) with the
validateflag.The script would exit printing out the error and with a non-zero code if validation failed.
Cleanup by deleting the
checks/test_generated_configsdirectory on exit.
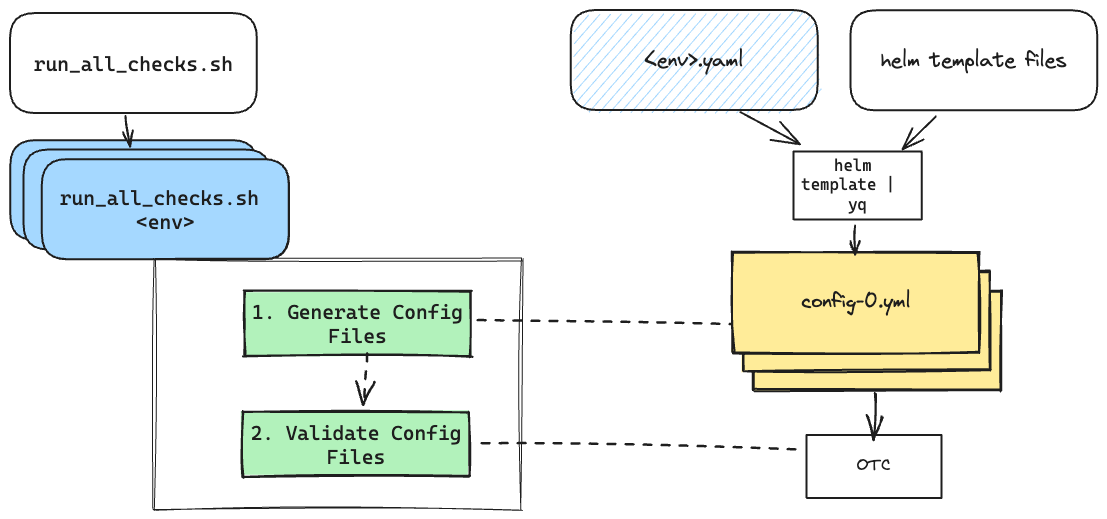
This post will centre around run_checks.sh as that is the meat of what I was working on, and here's what I learned.
The Flow
I like to set up my bash scripts as follows (there are probably some sort of conventions I should be following, but this has served me well so far).

Setting up for Success
Handle errors and let me know when things are going wrong.

Shout out to this amazing gist that explains it in great detail - but we started with this to set ourselves up for success (do you see what I did there?) This line does three things:
-e- tells Bash to bail out immediately on anynon-zeroexit codes (errors)-u- tells Bash to bail if any variable is not set (common in substitution operations)-o pipefail- ensure that any error results in an error for the whole script (i.e. "fail as a team")
For me, I like to set up my variables next as follows:
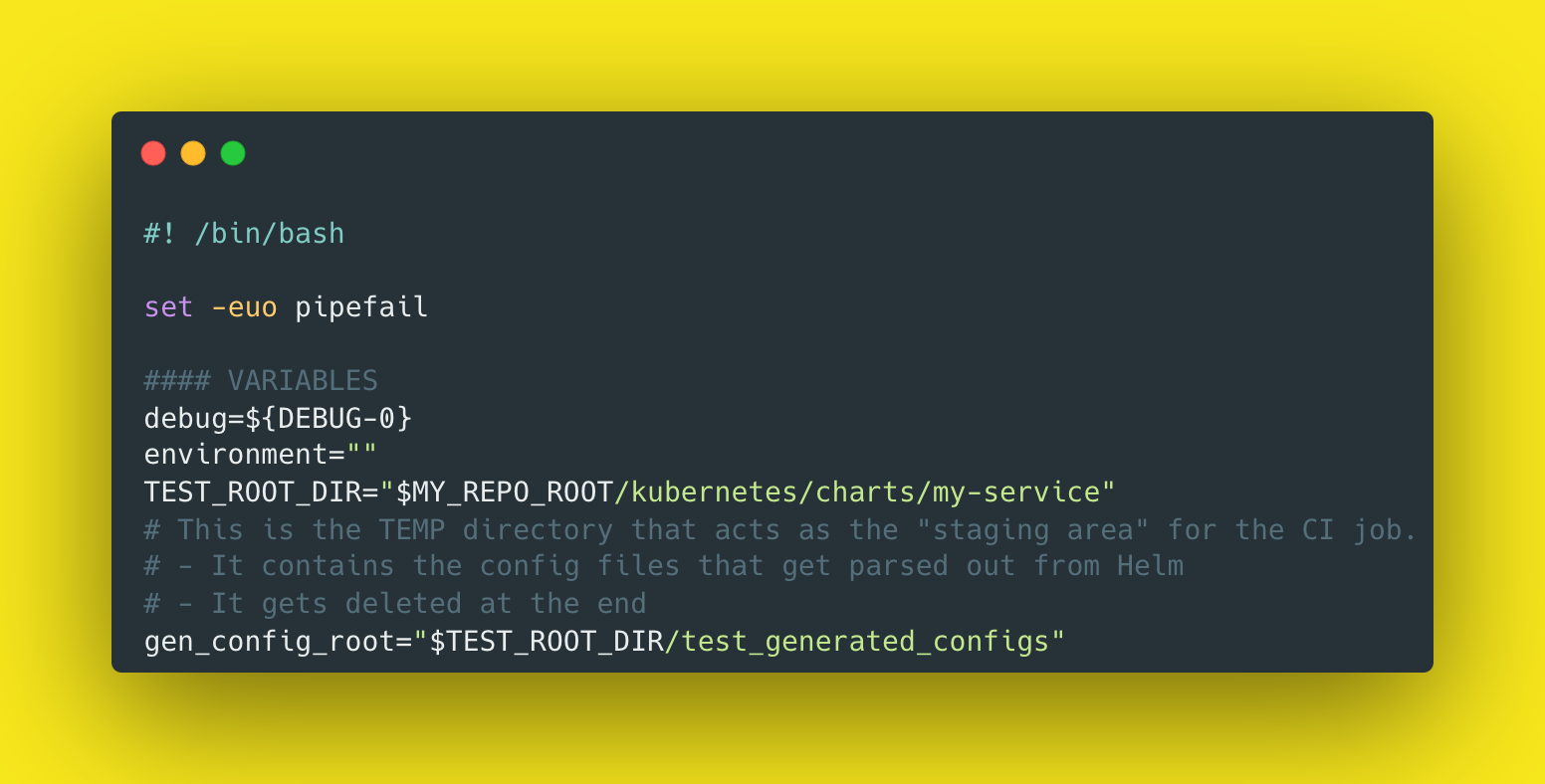
One thing I learned here was the use of debug=${DEBUG-0} which is essentially variable instantiation with a default.
This line says set debug to = the value of $DEBUG which might be a runtime param, and if not provided, set to 0
Functions
Personally, the next thing I like to set up in my script is the functions. To better illustrate how I built this up - I'll show both the functions and their invocation.
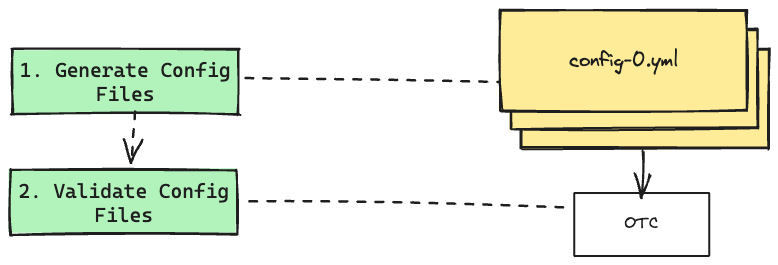
This is where the logic comes into play. From the functionality above, I've personally broken them down as follows:
0 - Bootstraping and Parse Args
1 - Generate Config Files
2 - Validate each Config File
3 - Cleanup

This helps us build our skeleton. We can then proceed with building out.
0 - Bootstrapping and Parsing Args
Determine which environment this script should generate and validate configuration files for.
#### MAIN
# 0. Bootstrapping & Parse Args
while getopts de: flag
do
case "${flag}" in
d)
debug=1
;;
e)
environment=$OPTARG
;;
\?)
usage
exit 1
;;
esac
done
shift $((OPTIND -1))
if [[ $environment == "" ]]; then
usage
echo >&2 "error: please provide the -e <environment> option (staging, development, public)"
exit 1
fi
Which uses getopts to parse command line arguments and allows you to use their short codes (i.e. -d for debug, -e for environment)
This is done in a while loop with a case statement (which is kinda like a switch) to assign values to their arguments.

Note that
/?)line. This tells the script that if theflagfrom any of the command line arguments are not indore- to print invoke theusagefunction.Note the
shift $((OPTIND -1))at the end which:
removes all the options that have been parsed by
getoptsfrom the parameters list, and so after that point,$1will refer to the first non-option argument passed to the script.
This means that if you have more to your command like run_checks.sh -e staging -d foo bar baz ; foo,bar and baz now moves up to the front of the "line" in positions $1, $2 and $3.
if [[ $environment == "" ]]; then
usage
echo >&2 "error: please provide the -e <environment> option (staging, development, public)"
exit 1
fi
If no the environment is specified, usage is invoked and the following error is logged to stderr.
So what's usage?
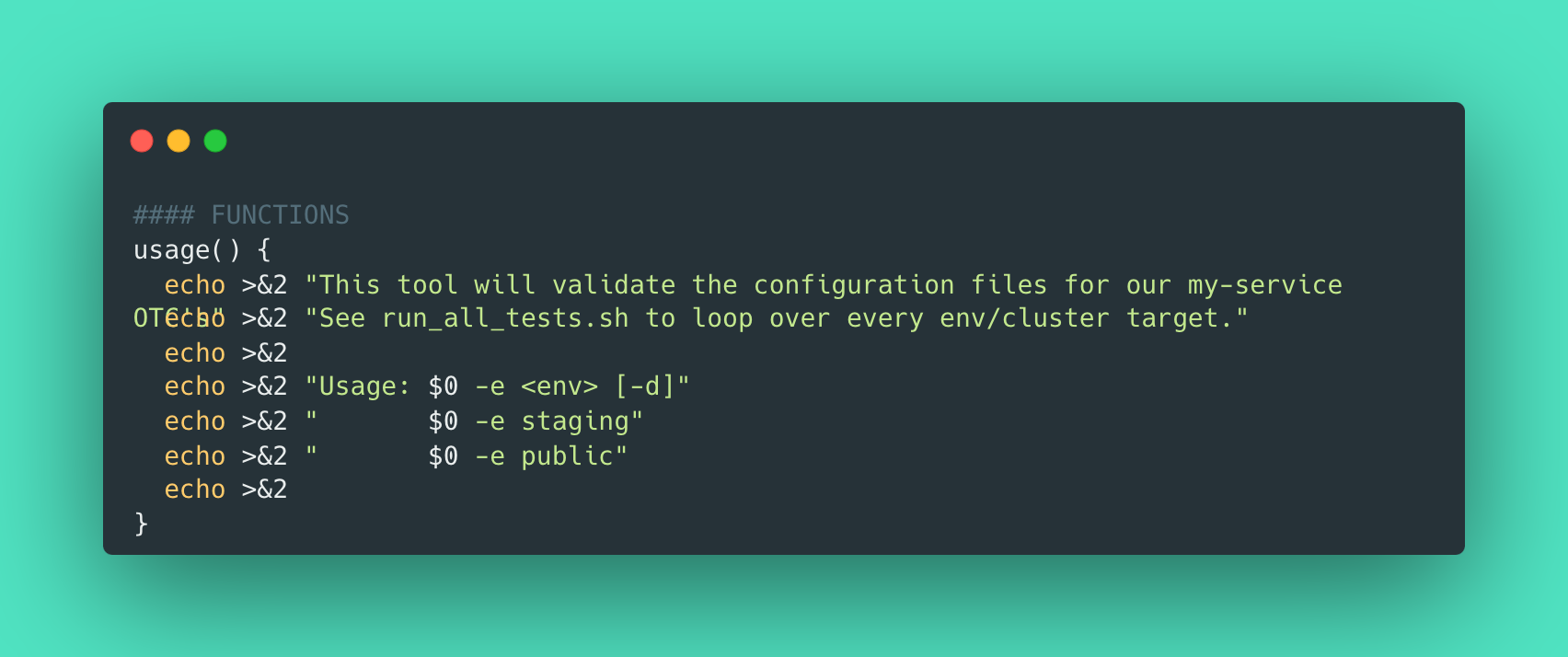
#### FUNCTIONS
usage() {
echo >&2 "This tool will validate the configuration files for our my-service OTC's"
echo >&2 "See run_all_tests.sh to loop over every env/cluster target."
echo >&2
echo >&2 "Usage: $0 -e <env> [-d]"
echo >&2 " $0 -e staging"
echo >&2 " $0 -e public"
echo >&2
}
Is our very helpful message that gets printed out on unexpected command line input to instruct the operator on what to do.
Checkpoint
This is what our script looks like now.
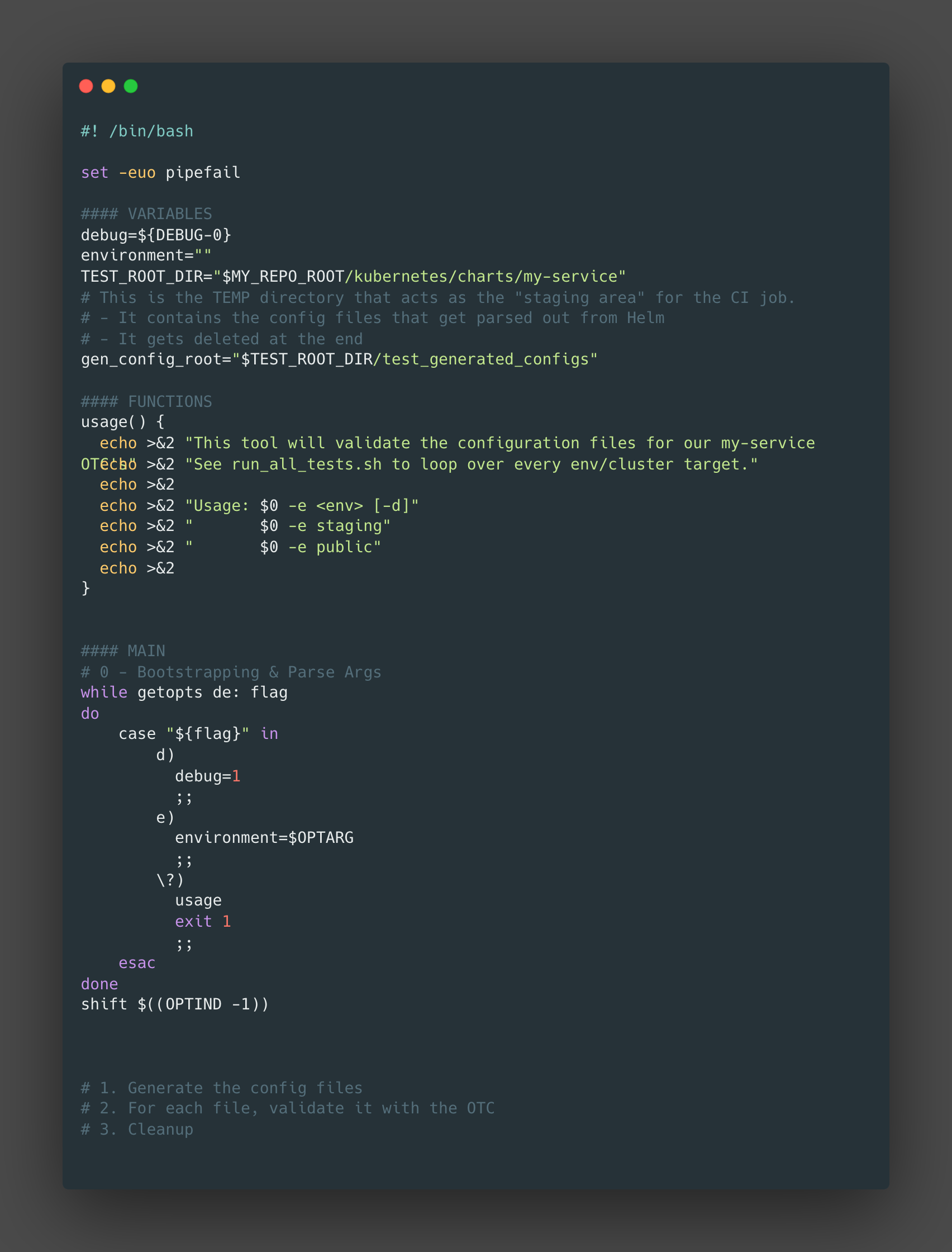
Next up we had to implement our steps:
1 - Generate the Config Files
Based on the <env> passed in, generate config files using our yq command.
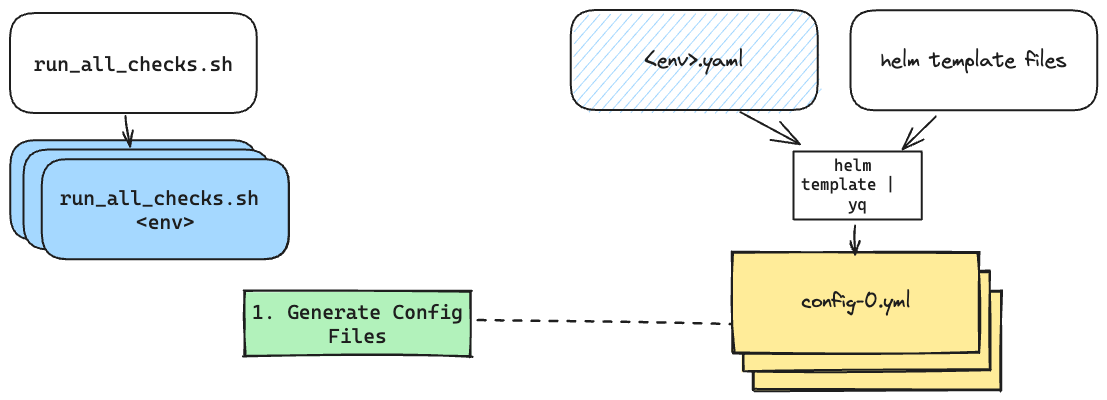
You'll recall that from our last blog post, we now had a handy dandy way of generating the config files using a yq command with the helm template
helm template -f staging.yaml -s templates/collector.yaml . | yq 'select(.kind == "OpenTelemetryCollector").spec.config' -s '"staging-config-" + $index
Now we had to "bashify" this to work with environments other than just staging.
First, we'd need to create a location for these files to live, like
/test_generated_configs/<env>Then we'd want to go ahead and render out each of the config files.
mkdir -p "$TEST_ROOT_DIR"/test_generated_configs/"$environment"
pushd "$TEST_ROOT_DIR" && eval "$(make_helm_template_command)"
popd
This is where we make use of pushd and popd to quickly CD in and out of our specific directory to run our command.
We run the command by using eval "$(make_helm_template_command)"
That's actually from our function here:
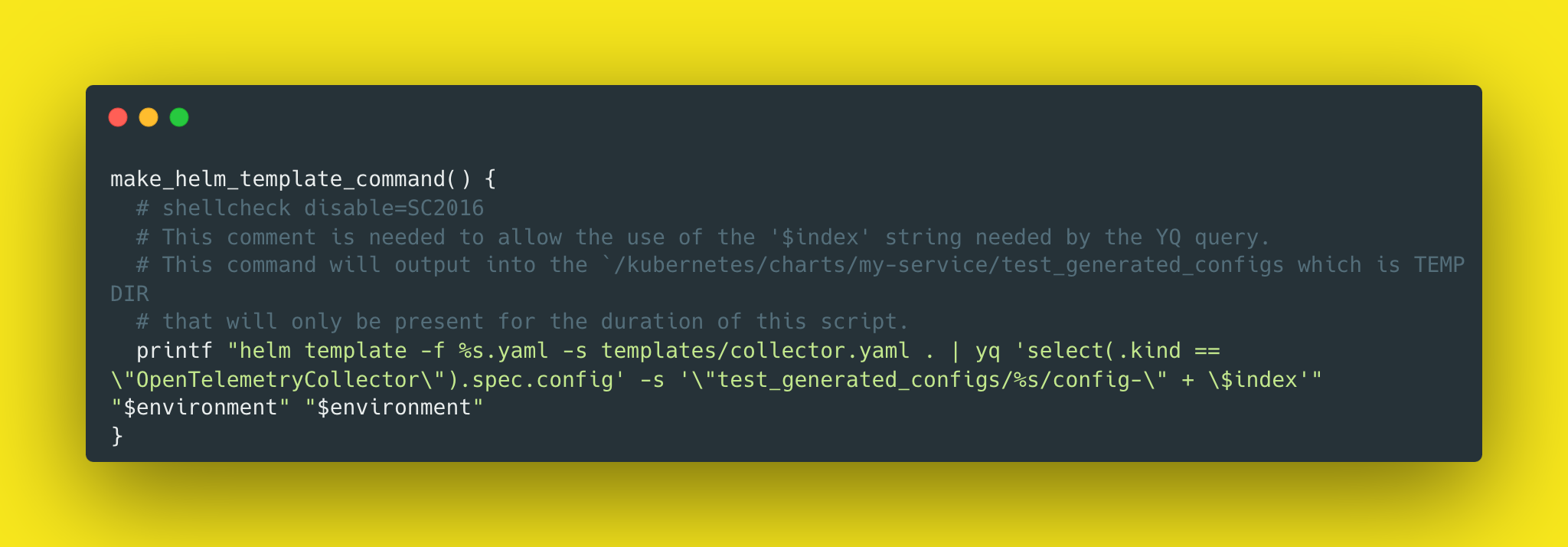
Once this is complete, there will be config files generated like this:
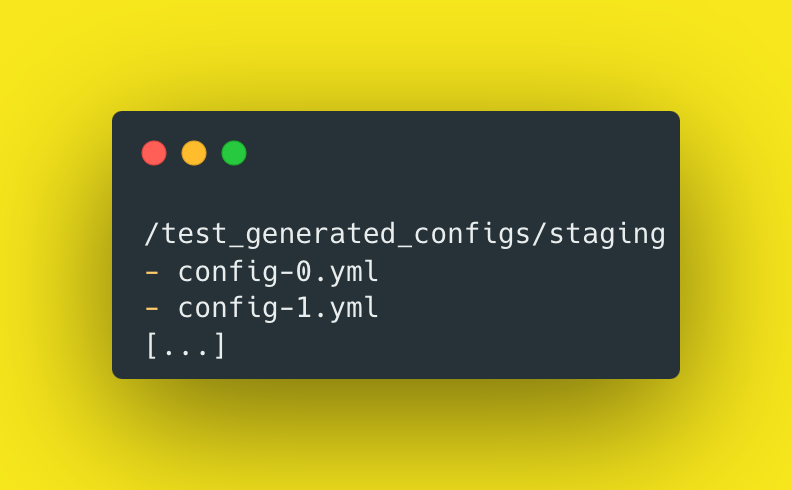
2- Validate each Config File
For each config file, pass it into the
validatecommand and check that it's valid.
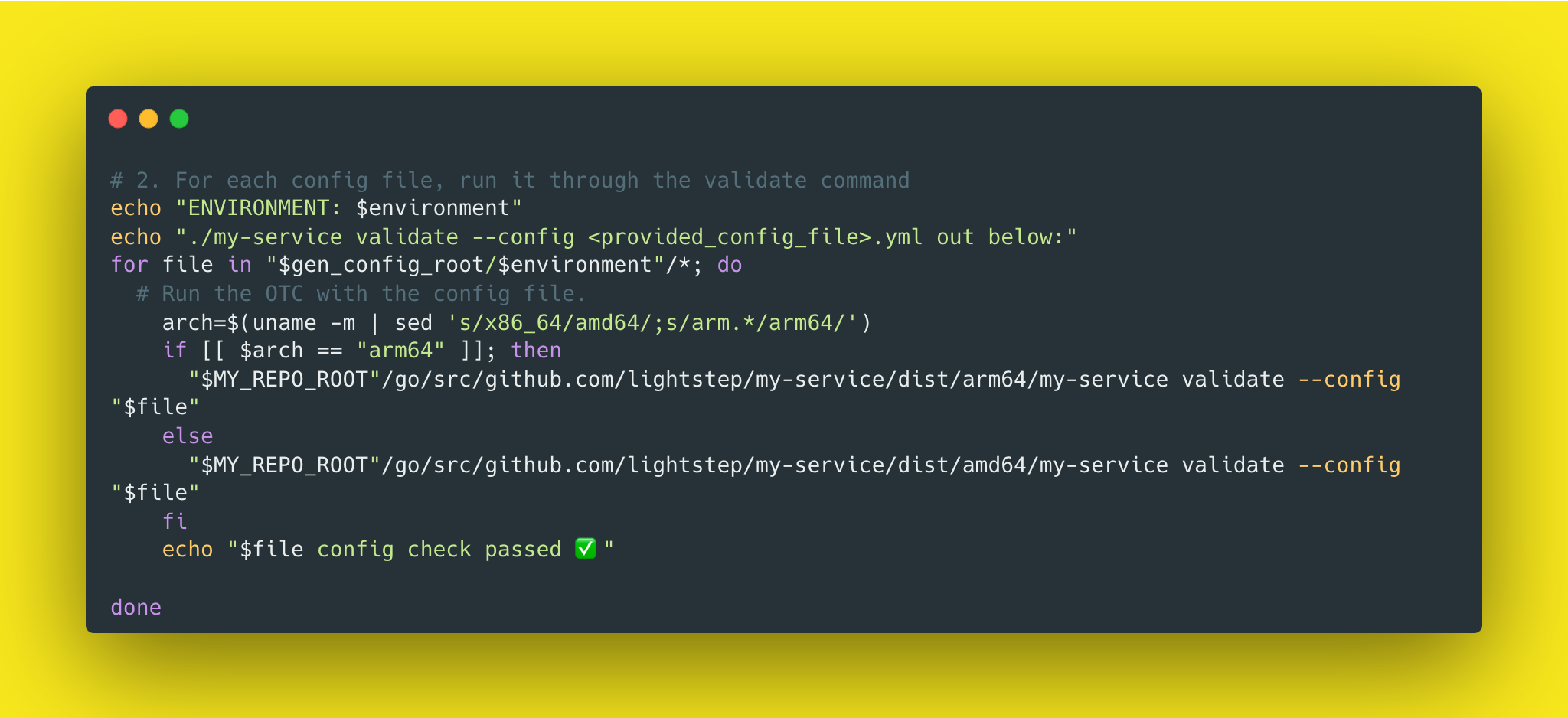
Due to our rollout of M1 laptops amongst our team, we've noticed a mismatch in the binaries we have to build for running locally and in our infrastructure. Specifically that M1 laptops use arm64 and our infra (like CI) uses amd64. Because of this, we have our binaries stored in arch-specific directories like dist/arm64 or dist/amd64.
Using arch=$(uname -m | sed 's/x86_64/amd64/;s/arm.*/arm64/') is a slick one-liner to figure out which arch is being used in the invocation of the script.
3 - Cleanup
Get rid of our temp files.
Finally, since these config files will no longer be used (and inf act, are generated at deploy time) we want to ensure we clean-up our mess files. To do so we use the cleanup function.
echo "$file config check passed ✅"
done
cleanup
Which looks like this:
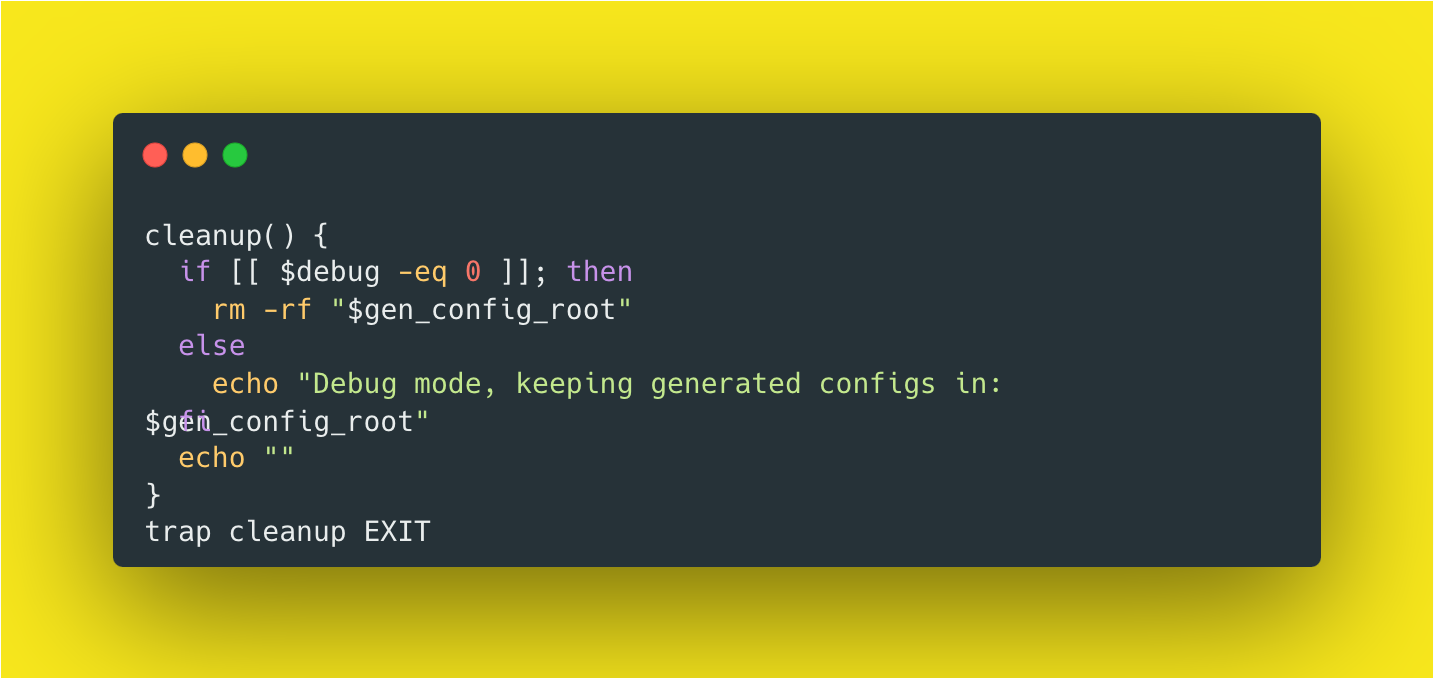
Where we tell it not to clean up the files if we're in debug mode (so we can examine them after the fact) or delete the directory otherwise.
Note the trap <function> EXIT which is known as an "exit trap". This tells the bash script to always run this function whenever the script exits for any reason. This is great because it ensures that our config file directories will be deleted whenever the script ends or even if it errors out.
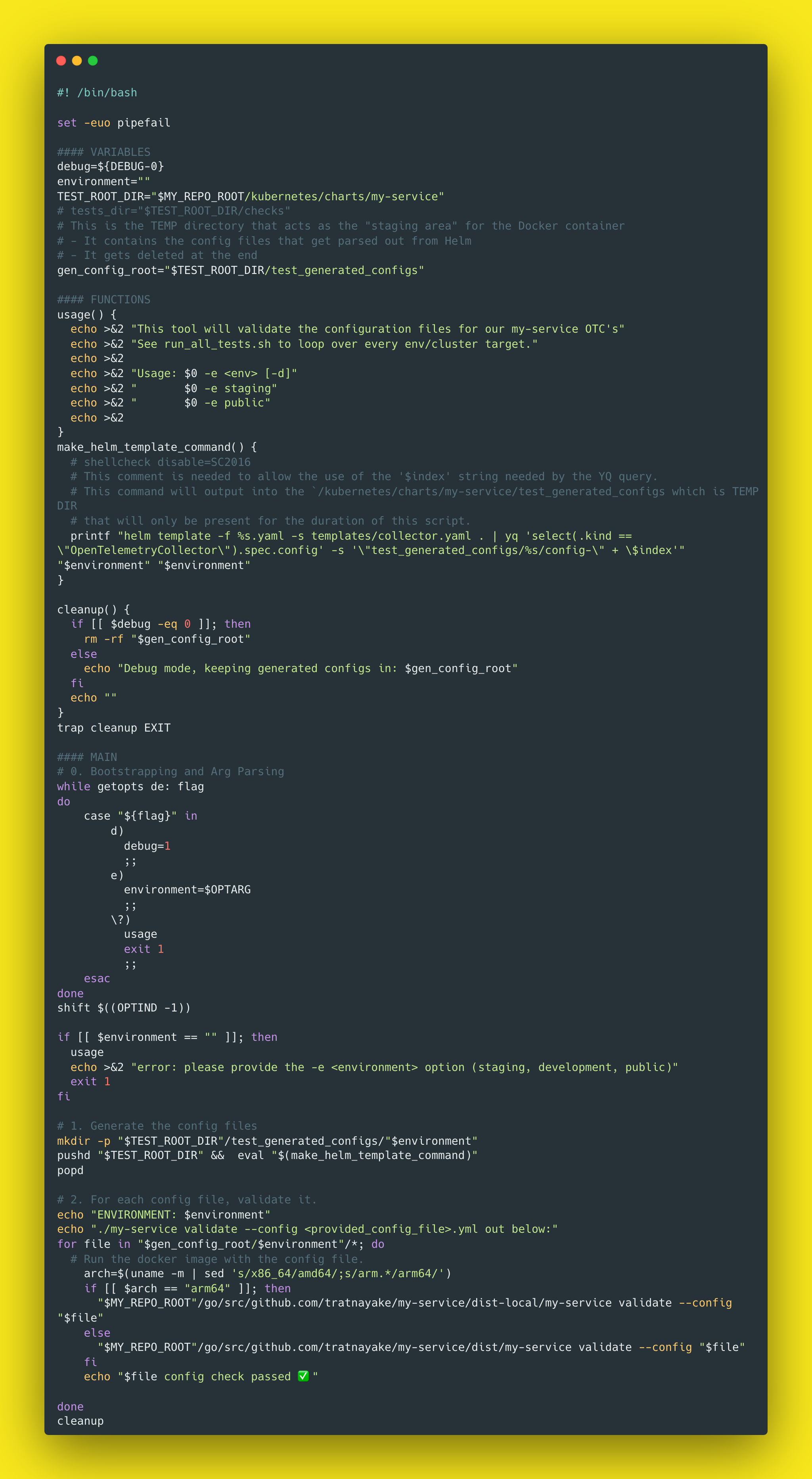
Finally, our whole script looks like this:
Bonus
In trying to get my scripts uploaded, I noticed that our CI pipeline's linter kept on yelling at me for some bash-related things. Turns out that these were all coming from a linting step that used shellcheck.
To fix these errors - I downloaded the shellcheck VS Code Extension which is fantastic because, not only will it give you an explanation of the issue within your IDE, it will allow you to quickly fix most issues as well!
Conclusion
Sharpening your Bash skills can greatly improve your ability to generally get things done as an engineer. Specifically in SRE - it helps with things like managing CI pipelines and working with tools like Open Telemetry Collectors. By breaking down tasks into manageable functions, using error handling, and leveraging helpful tools like getopts, you can create efficient and maintainable scripts. Additionally, incorporating linters like shellcheck and its VS Code Extension can help you quickly identify and fix errors, ensuring your scripts are reliable and robust.



